我近期在研究一个 NLP 项目,根据项目的要求,需要能够通过设计算法和模型处理单词的音节 (Syllables),并对那些没有在词典中出现的单词找到其在词典中对应的押韵词(注:这类单词类似一些少见的专有名词或者通过组合产生的新词,比如 Brexit,是用 Britain 和 exit 组合在一起创造出来表示英国脱欧的新词)。在这两个任务中,能够对单词的发音进行预测是非常有必要的。本文详细记录我解决该问题的过程,希望能够对初学者和具有一定经验的朋友有所帮助。本文代码实现均基于 Python 3 和 Keras 框架。现在让我们开始吧!
我们将使用 CMU Pronunciation Dictionary () 作为我们的数据集,该词典收录了将近 134000 个单词以及对应的音标拼写。譬如「苹果」的英文单词「apple」出现在该词典中的形式为:「AE1P AH0L」。其中每一个去除数字后的音标块(token),表示一个发音(如 AE,P,AH 等),在语言学里称之为「音素」。音素结尾的数字表示发音的声调大小,被称为「词汇重音标记」。由于只有元音才有重音标记,所以在英文中有 39 个唯一的音素和 84 个独特的符号。


接下来,在我们将数据交给学习算法之前,我们需要想办法将单词和发音用数值的形式表示。在这里我们将单词看作是字符序列,发音看作音素符号的序列(包括重音标记)。我们可以给每一个字符和音素赋予一个数值,然后我们就可以将它们表示为 One-Hot 向量的形式。根据单词的字母预测其发音可以看作一个字音转换问题。我们需要告诉模型语音拼写从哪里开始又从哪里结束,因此我们引入两个独特的开始和结束标注符号,在这里我使用的制表符\t 和换行符\n分别来表示。

用这些数字型的 ID 直接作为模型的输入看起来非常诱人,但是这样做的话会使得字母/音素之间隐含一种并不真正存在的关系。例如,由于 A=4,C=6,和 U=24,意味着 A 和 C 在某种程度上比 A 和 U 更相似(因为 4 更接近 6)。显然事实情况并非如此。相反,我们可以使用我们的 ID 映射来将字符和音素转换为 one-hot 向量():
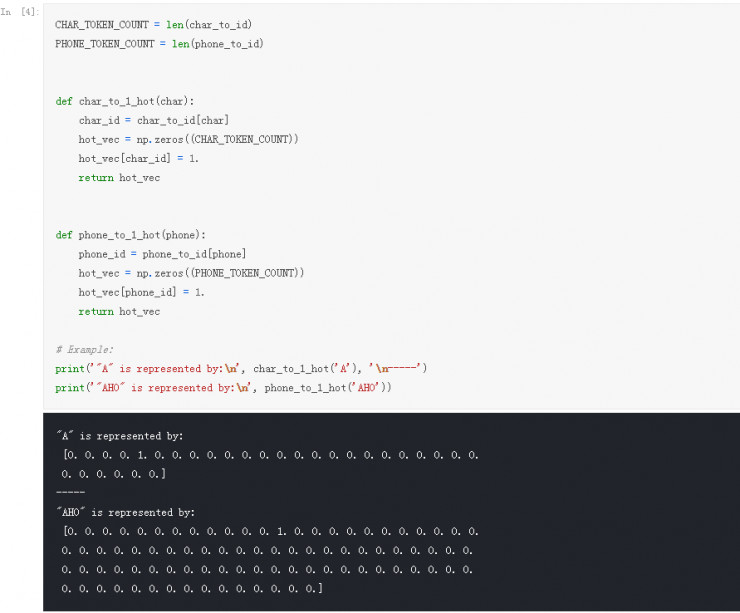
现在我们有一种数值化表示字母和音素的方法,我们可以把整个数据集转换成两个大的三维矩阵(也可以被称为张量):

由于我们处理的是序列数据,对于序列数据来说,RNN 模型 [视频, 博客] 最适合不过了。让我们先从基于 RNN 的 LSTM 模型 [视频, 博客] 开始上手吧!
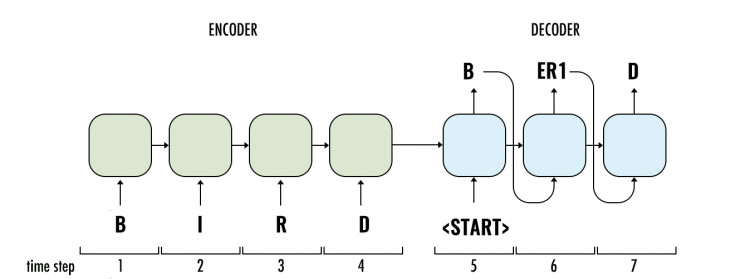
需要注意的是,单词中的字符数通常与发音中的音素的数目不相同。我们的输入和输出之间并不存在一对一的映射。出于这个原因,我们将创建一个带有编码器 (encoder) 和解码器 (decoder) 两个部分的 seq2seq [博客链接](模型。
我们一次给编码器 (Encoder) 输入一个字符,然后将编码器 (Encoder) 的状态变量传递给解码器 (Decoder)。我们需要稍微不同的解码器 (Decoder) 设置的训练与测试时间。在训练过程中,我们将给解码器提供正确的读音,一次一个音素。在每个时间步长,解码器将预测下一个音素。在推理过程(预测发音)中,我们不知道正确的音素序列(至少在理论上是这样)。因此,我们将把解码器 (Decoder) 的输出从前一个时间步长输入到下一个时间步长作为输入。这就是为什么我们需要前面提到的 START_PHONE_SYM 的原因。这里的流程图说明了我们的模型在测试集上如何进行预测:
我们在上面创建的 phone_seq_matrix 将会作为我们 Decoder 的输入。我们将通过将所产生的发音序列向左移动 1 步来创建解码器输出。因此解码器输出将不包含开始标记:
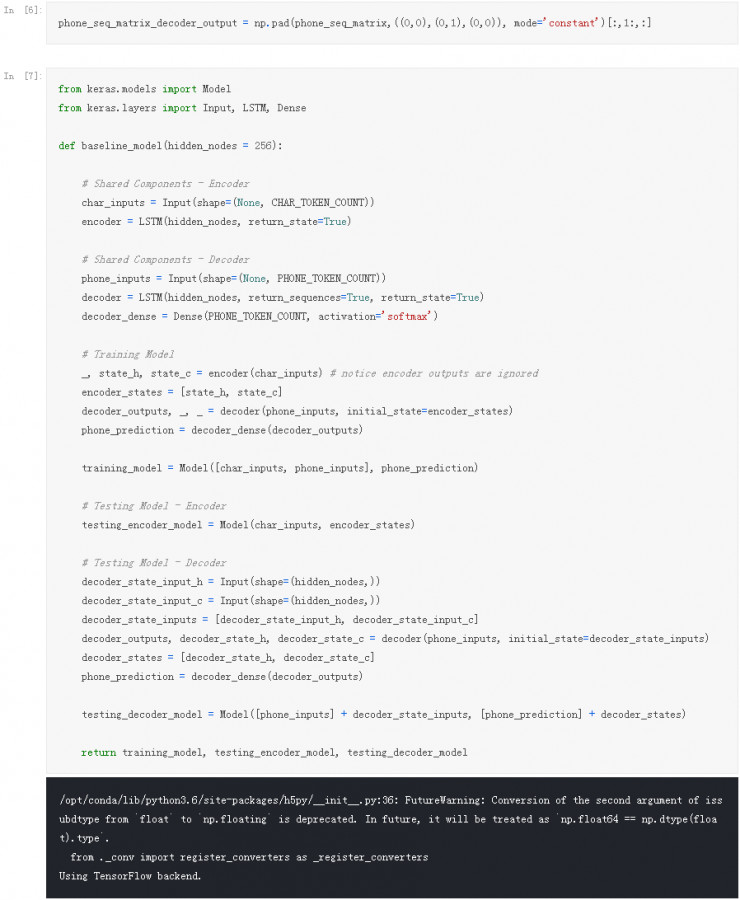
首先,我们需要从数据集中划分出测试集以便后期能对模型性能进行评估。为了能在 Kaggle 上运行,我们会将测试集的大小减少至 100 个数据样本。

现在,我们将开始训练我们的 seq2seq 模型直到它开始过拟合为止。我们需要一个泛化能力强的模型,对于在训练集中未出现的样本也能有不错的表现。所以在训练过程中我们会保存那些在验证集上有最低 loss 的模型。

在训练过程中,在每个时间步长,我们给我们的解码器正确的输出,这个输出来自于以前的时间步长。如前所述,我们不知道测试时间的正确输出是什么,只有解码器预测的是什么。所以我们需要一个不同的程序来进行预测。
4. 将更新的状态和第一个音素预测作为输入输入到解码器,以得到第二个预测音素。
5. 将更新的状态和第二个音素传递到解码器以获得第三个音素等,直到解码器预测出停止标志(stop token),或者我们达到最大发音序列长度。


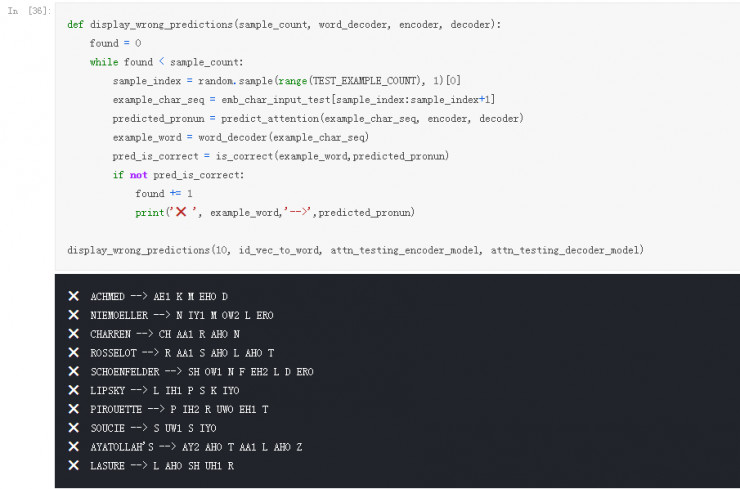
初步的预测结果看起来效果不错,部分错误的预测也完全可以理解... 毕竟我也不会读
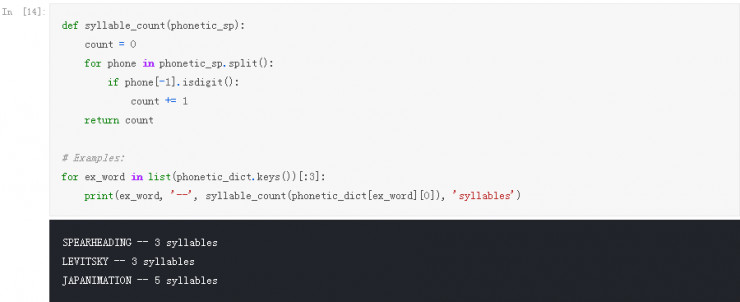
1. 基于音节计数的准确率:记住这个项目的最初目标之一是能够计算字典中没有出现的单词的音节数量。从语音拼写中获得音节的计数与用重音符号计算音素一样简单:
2. 完全准确率:这个指标更加的严格,要求在测试集中每一个预测的音素和重音符号均正确而且在预测顺序上也要正确,符合这样三个要求的预测正确样本数占测试集样本总数的百分比即为完全准确率。
3. BLEU 评分均值:该评分的值介于 0.0-1.0 之间,1.0 表示预测完全正确,0.0 表示预测完全错误。该评价指标经常用于评估机器翻译模型的水平,如果你稍微想一想,这个和我们的发音预测还是蛮相似的。可以点开此链接()查看更多。

很棒!模型目前取得的分数看起来还不错!现在让我们看看有没有其他什么办法提升我们的 Baseline 模型。
在我们继续之前,我们先将我们的 Baseline 模型从 TensorFlow 计算图中移除,以便节省系统内存。

我们将采用 Embedding 技术 [视频链接, 博客链接] 来表示字母和音素,而不是将字母和音素表示为 One-Hot 向量,所以我们的模型将学习它自己的每一个符号的表示。Embedding 所产生的向量比一般的 One-Hot 向量更具有描述性的表示。想想字母 C 有时听起来像「K」,其他时候听起来像是 S。理论上,我们的嵌入层应该学会这些潜在的关系。希望这将有助于提高我们的评测分数。
Keras 的 Embedding 层将会自动 ID 转换为 Embedding 向量,所以我们需要改变我们单词数据的表示方式。这次我们将只存储字符和音素 ID 而不是它们的 One-Hot 向量表示。为了简单起见,我们将继续使用音素的 One-Hot 向量表示作为为解码器的输出层。

理论上来说我们需要重新划分训练集和测试集。但需要注意的是,我们设置的 random_state 与以前相同,所以重新划分后的集合中的样本都是相同的。这也意味着,我们不需要为我们的 One-Hot(解码器输出)音素矩阵重新划分,因为我们正在重用它。

最后,我们可以添加新的嵌入层到我们的基线模型。因为他们给我们的网络增加了更多可训练的参数,所以更容易过拟合。让我们通过添加一些 Dropout 层来避免这种情况:
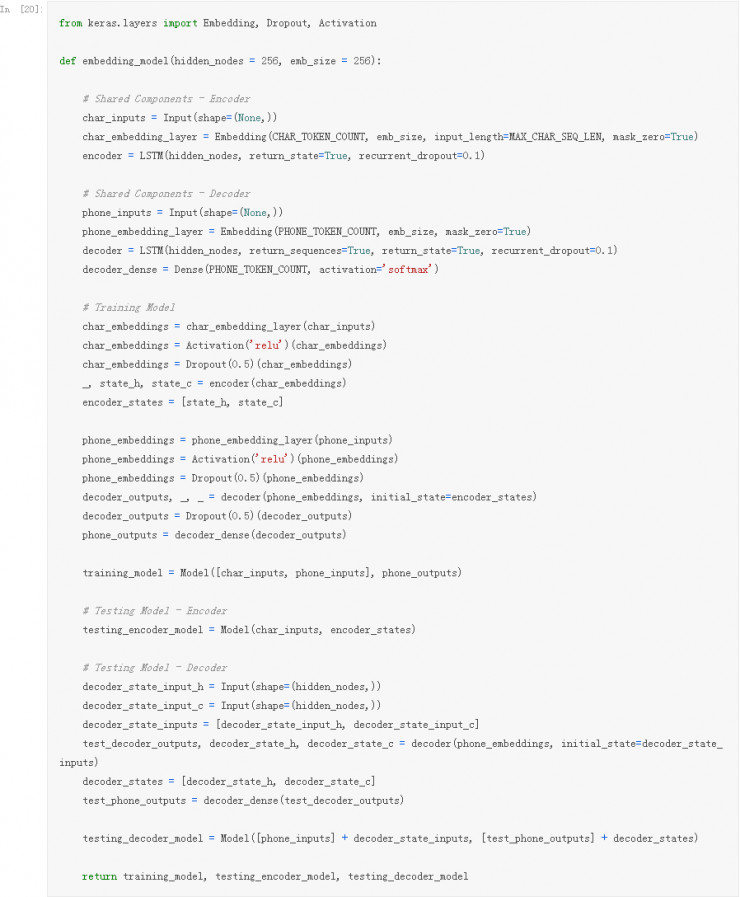

为了评估我们的 Embedding 模型我们需要添加一个新的帮助方法来将单词的 ID 转换为原来的单词:

在评测我们的新模型之前,我们需要重写预测方法来处理 ID 形式表示的结果(而不是 one-hot 形式)
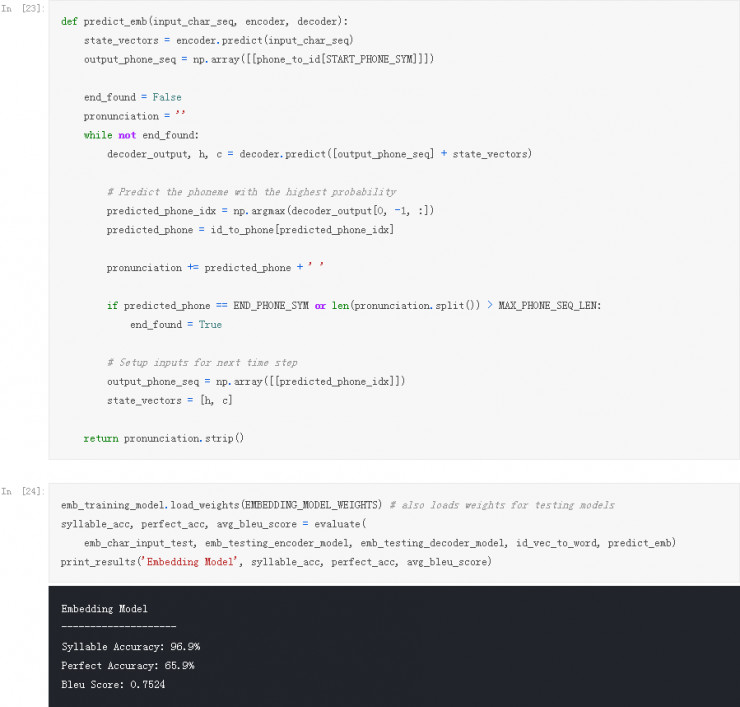
让我们提取从模型学习到的 Embeddings 并用 t-SNE 技术来将它们可视化呈现一下吧!

相当 Cool!可以看到那些发音类似的字母和音素聚类到了一起。现在让我们再次重置一下 TensorFlow 计算图并继续探索其他模型吧!
到目前为止,我们的 RNN 模型只运行在一个方向上,我们的编码器和解码器之间的唯一连接是我们在它们之间传递的 2 个状态变量(从编码器的末端开始)。对于较长的单词和发音,这些状态变量可能不足以捕获整个单词,并且来自编码器的信号有可能丢失。
Attention 注意力机制是避免这个问题的一种方式。我们需要对模型的结构做一些大的改变。我们将使用编码器的输出,而不是它的内部状态变量。这使得编码器很容易双向进行。在一个单词中,关于下一个以及前面的字符的信息应该会在每个时间步产生更好的编码。

由于我们的模型、输入和输出已经从我们以前的 2 个版本中改变了很多,所以我们需要稍微重写我们训练的过程。当我们开始过拟合或者达到结果一直处于「平缓」状态的时候我们就停止训练,并将达到最佳验证集损失时候的权重以文件的形式存储起来。

我们还需要对我们的 baseline 模型的预测方法做一些修改,使之与我们的注意力模型能够协同工作:
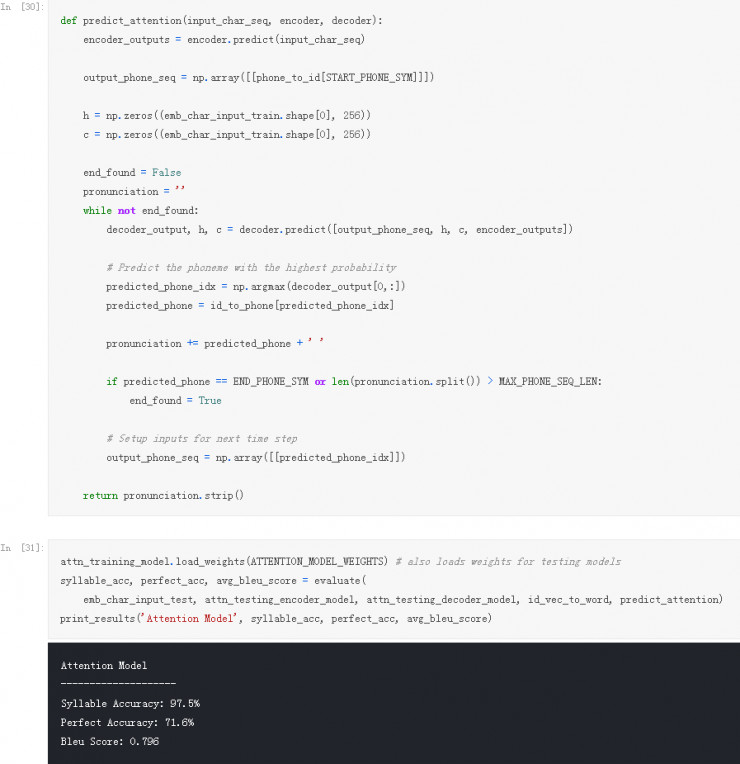
从结果来看,新的 Attention 模型在三个指标上均有进一步的提升!
我们已经知道了哪个模型效果最好,现在的问题是我们的模型在其过拟合之前需要训练多久以及超参数如何调整到最优。让我们在全部训练数据集上训练一个最终版的模型吧。
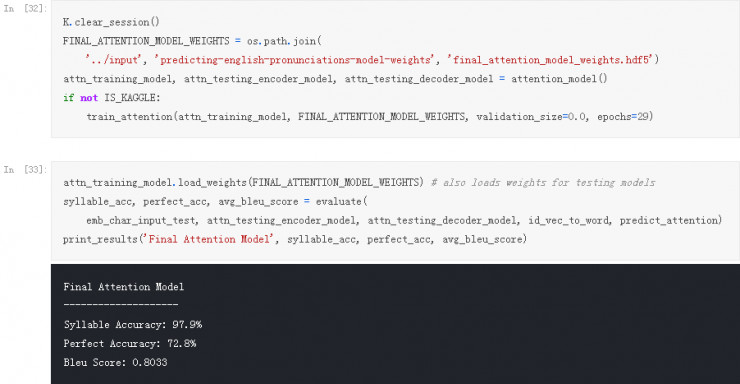
目前当我们利用模型作出预测的时候,在每一个时间步(Time Step)选择最大概率的单个音素并不断继续这个过程。但是我们真正想要的是有着最大概率的音素序列这样一个整体。如果我们早早做出错误的选择,我们很容易最终得到一个不太理想的预测,而我们永远也不会知道。一种解决方案是搜索整个输出空间,并选择所有可能的序列中最好的。这将确保我们找到最有可能的序列(至少根据我们的模型),但这将花费大量的精力。
相反,我们可以使用集束搜索 [视频链接, 博客链接] 这种介于两种极端之间的 Trick。在每个时间步长,我们保持最可能的序列并向前移动。增加 k 的值意味着我们更有可能找到最优序列,但同时增加搜索时间。


不得不吐槽一下英语真是一门奇怪的语言。对于一些新的单词,甚至是以英语为母语的人们也会读错。发音规则复杂多变,有时候根本无法理解。感兴趣的话可以看看这个 Yotube 视频()上的一些例子。75.4% 的准确率虽然看起来不高,但是综合语言的特点来看,我觉得这还算是个不错的分数。
使用两个单独模型:模型 1 只预测音素,而模型 2 在适当的位置加上重音符(数字)。知道最后序列的长度意味着我们的第二个模型的解码器很容易是双向的。了解过去和将来的元音发音似乎有助于改善我们对重音符的预测效果。
进一步超参数调整 实际上在本文我们真的没有花太多时间调整我们的超参数。如果多花点时间的话,应该很容易找到一些更好的价值,并提高我们的分数。
使用更复杂的模型 将另一个递归层添加到编码器或在解码器后加入一些 1D 卷积层是值得尝试的。
当然这绝不是发音预测问题的最先进的方法,距离达到 SOTA 水平还远着呢!如果你对更好的解决方案感兴趣,一定要拜读一下这些论文:
转载请注明出处。

 相关文章
相关文章

 精彩导读
精彩导读


 热门资讯
热门资讯 关注我们
关注我们
